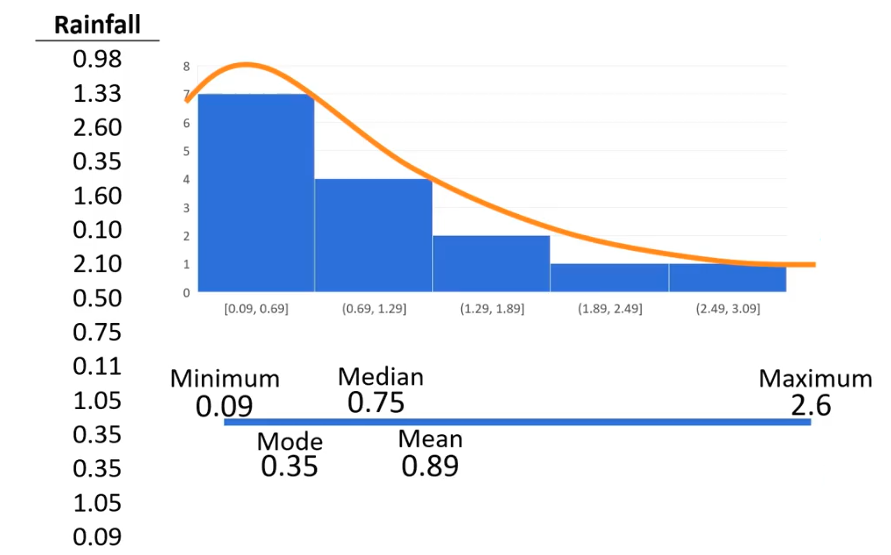
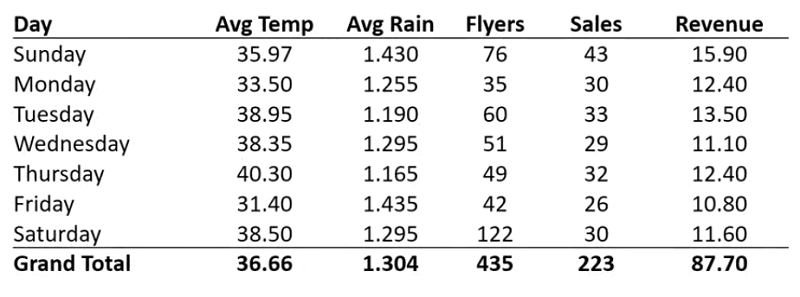
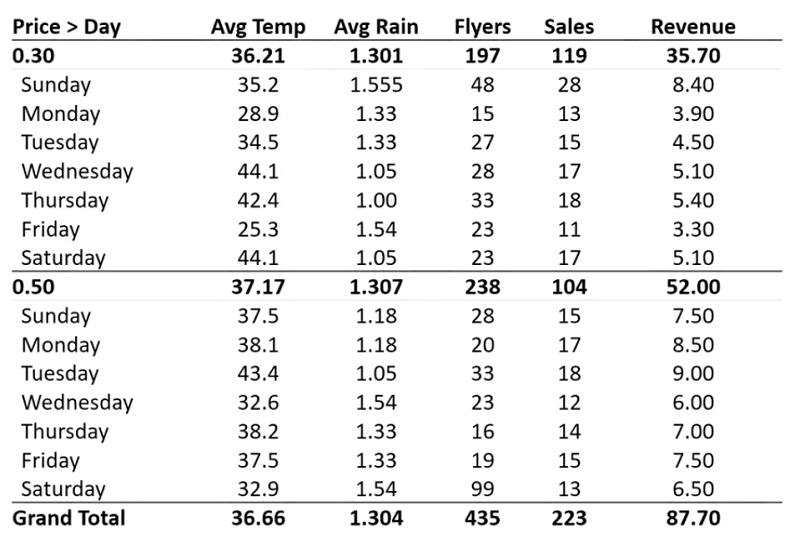
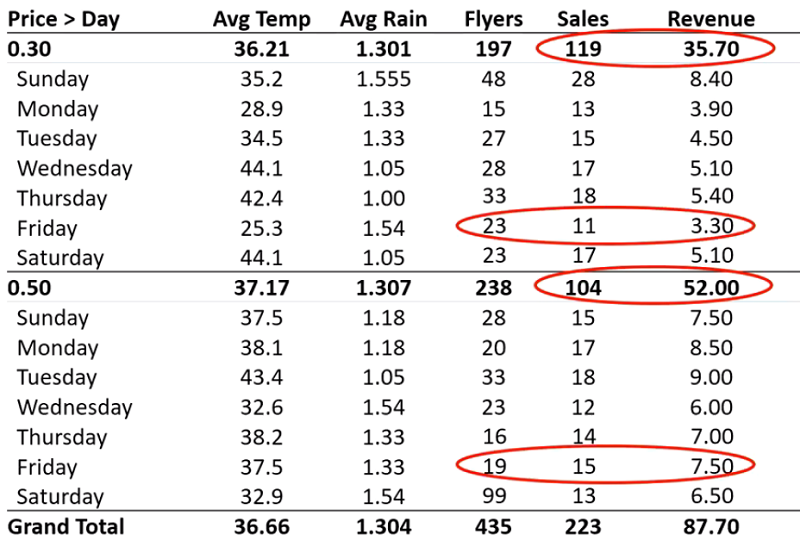
این رشته توییت رو که مربوط به چند سال پیشه به طور اتفاقی دیدم. به نظرم جالب بود و برای اینکه در دسترستر باشه و هر از چندگاهی مرورش کنم، تصمیم گرفتم یه ترجمه خودمونی ازش اینجا بذارم. هر چند که مثل همیشه، خوندن متن اصلی مفاهیم رو بهتر منتقل میکنه. و البته حتما همهی قسمتهاش برای همه جای دنیا کاربردی نیست، اما یه درسهایی میشه ازش گرفت.
۱- در جستجوی ثروت باشید، نه پول یا مقام. ثروت، داراییهایی است که حتی بدون حضور و توجه دائمی (مثلا زمانی که در خواب هستید) تولید درآمد میکنند. اما پول، ابزاری است که افراد برای تبادل ثروت یا وقتشان با یکدیگر از آن استفاده میکنند. مقام و موقعیت هم جایگاه شما در سلسله مراتب جامعه است.
۲- باور داشته باشید که خلق ثروت از راههای درست و اخلاقی ممکن است. اگر در خلوت خود ثروت را بد میدانید، از آن دور خواهید شد.
۳- از افرادی که دنبال مقام هستند فاصله بگیرید. آنها پست و مقام خود را با حمله به کسانی که به دتبال خلق ثروت هستند به دست میآورند.
۴- نخواهید که با معامله وقت خود با دیگران ثزوتمند شوید. شما باید مالک بخشی از یک کسب و کار باشید تا به آرادی مالی برسید.
۵- شما با دادن چیزی به جامعه که آن را میخواهد، اما نمیداند چطور آن را به دست بیاورد ثروتمند خواهید شد. این کار را باید در ابعادی انجام دهید که مقرون به صرفه باشد.
۶- حوزهای را انتخاب کنید که بتوانید برای مدت طولانی در آن فعالیت کنید و افراد فعال در آن حوزه هم برای مدت طولانی مشتری شما باشند.
۷- اینترنت به طور گستردهای به وسعت فضای مشاغل افزوده است. خیلی از افراد هنوز این موضوع را درک نکردهاند.
۸- دنبال کارهایی باشید که میتوان آنها را در چرخه تکرار قرار داد. هر چیزی در زندگی که میبینید بازدهی مناسبی دارد، چه در مورد ثروت، چه در مورد روابط یا دانش، از سود مرکب بهره میبرد.
۹- افرادی باهوش و پر انرژی، و از همه مهمتر صادق را به عنوان شریک تجاری خود انتخاب کنید.
۱۰- با افراد شکاک و بدبین شریک نشوید. آنها معتقدند همه فقط در جهت رشد و پیشرفت خودشان حرکت میکنند.
۱۱- ساختن و فروختن را یاد بگیرید. اگر بتوانید این دو کار را انجام دهید، کسی نمیتواند شما را متوقف کند.
۱۲- خود را به دانشی اختصاصی مجهز کن، به طوری که در آن حوزه بتوان رویت حساب کرد، و سپس حداکثر بهره را از آن ببر.
۱۳- منظور از دانش اختصاصی چیزیست که نمیشود برای آن آموزش دید. اگه جامعه بتواند در آن حوزه تو را تعلیم دهد، هر کس دیگری را هم میتواند تعلیم داده و با تو جایگزین کند.
۱۴- شما با دنبال کردن حس کنجکاوی خالص و اشتیاقی که نسبت به موضوعی دارید میتوانید به دانش اختصاصی در آن زمینه دست پیدا کنید، نه با پیگیری چیزی که الان مد شده است.
۱۵- رسیدن به دانش اختصاصی، برای شما مثل یک بازی ولی برای دیگران مثل انجام یک وظیفه خواهد بود.
۱۶- یادگیری دانش اختصاصی از دیگران، از طریق شاگردی کردن امکانپذیر خواهد بود و نه در مدارس.
۱۷- دانش اختصاصی اغلب بسیار فنی یا خلاقانه است. نمیتوان آن را به دیگران برونسپاری یا استفاده از آن را به فرآیندی خودکار تبدیل کرد.
۱۸- مسئولیت را با آغوش باز بپذیر و برای پذیرش ریسکهای تجاری با مسئولیت خودت آماده باش. اینها چیزهایی هستند که جامعه در قبال آنها به تو پاداش خواهد داد.
۱۹- افرادی که بیشتر از بقیه میتوان روی آنها حساب کرد، دارای هویتی غیرمعمول، شناخته شده و ریسکپذیر هستند: اُپرا، ترامپ، کانیه و ایلان.
۲۰- ارشمیدس میگوید: به من اهرمی به اندازهی کافی بلند و جایی برای ایستادن بده تا زمین را جابهجا کنم.
۲۱- ثروت نیاز به اهرم دارد. اهرمِ یک کسب و کار، سرمایه، افراد و محصولاتی هستند که تولید یک واحد بیشتر از آنها هزینهای نداشته باشد. (مثل کد نرمافزاری و رسانه)
۲۲- سرمایه یعنی پول. برای افزایش آن، با مسئولیتپذیری از دانش اختصاصی خود استفاده کن.
۲۳- نیروی کار یعنی افرادی که برای شما کار میکنند. این قدیمیترین و مورد بحثترین شکل اهرم است. داشتن نیروی کار، والدین شما را تحت تاثیر قرار خواهد داد، اما زندگی خود را صرف رسیدن به آن نکنید.
۲۴- سرمایه و نیروی کار اهرمهایی وابسته به دیگران هستند. همه برای رسیدن به سرمایه تلاش میکنند، اما کسی باید باشد که به دیگران سرمایه بدهد. همه به دنبال مدیر شدن هستند، اما کسی باید باشد که برای دیگران کار کند.
۲۵- کدهای نرمافزاری و رسانه، اهرمهایی بدون نیاز به دیگران هستند. افرادی که اخیرا ثروتمند شدهاند از این اهرمها استفاده کردهاند. میتوان نرمافزار و رسانهای خلق کرد که وقتی شما خوابید برای شما کار کنند.
۲۶- ارتشی از رباتها به طور رایگان در دسترس شما قرار دارند: آنها در مراکز دادهای هستند. از آنها استفاده کنید.
۲۷- اگر نمیتوانید کدنویسی کنید، کتاب بنویسید، وبلاگنویسی کنید، یا ویدئو و پادکست ضبط کنید.
۲۸- اهرمها قدرت ادراک شما را چند برابر میکنند.
۲۹- ادراک نیازمند تجربه است، اما با یادگیری مهارتهای پایهای میتوان سریعتر به آن رسید.
۳۱- مهارتی به نام «تجارت» وجود ندارد. از مجلات و کلاسهایی که این عنوان را دارند دوری کنید.
۳۲- در مورد اقتصاد خُرد، نظریهی بازیها، روانشناسی، متقاعدسازی، اخلاقیات، ریاضیات و کامپیوترها مطالعه داشته باشید.
۳۲- «خواندن» از «گوش دادن» و «انجام دادن» از «تماشا کردن» سریعتر است.
۳۳- تا زمانی که تقویم کاری مرتبی ندارید، حتی یک قهوه هم ننوشید.
۳۴- برای خود یک نرخ ساعتی تعیین کنید. اگر دستاورد انجام کاری، کمتر از نرخی است که برای زمان خود تعیین کردهاید، از انجام آن کار صرفنظر کنید. اگر سپردن کار به دیگران، هزینهای کمتر از نرخ مشخص شما دارد، انجام آن را به دیگران بسپارید.
۳۵- تا جایی که برایتان ممکن است سخت کار کنید. هر چند، اینکه با چه کسی و روی چه چیزی کار میکنید مهمتر از این است که چقدر سخت کار میکنید.
۳۶- در کاری که انجام میدهید بهترین شوید. کاری را که انجام میدهید اینقدر بازتعریف کنید تا به چنین جایگاهی برسید.
۳۷- هیچ طرحی که فورا شما را پولدار کند وجود ندارد. اما دیگران با فروش چنین طرحهایی به شما ممکن است پولدار شوند.
۳۸- از دانش اختصاصی و اهرمها استفاده کن، در نهایت به آنچه استحقاقش را داری خواهی رسید.
۳۹- وقتی در نهایت ثروتمند شدید، متوجه میشوید که این چیزی نبود که در ابتدا به دنبالش بودید. اما این مسالهی امروز شما نیست.