این دومین بخش از خلاصهی مجموعهی «دورهی مقدماتی data science» هستش.
چیزی که مشخصه اینه که data science در مورد کاوش دادههاست. اما واقعا به چه چیزی داده گفته میشه؟
با یه مثال ساده شروع میکنیم. فرض میکنیم که «رُزی» تو وقت آزادش کنار خیابون لیموناد میفروشه و به دقت اطلاعات فروشش رو به صورت زیر ثبت میکنه:
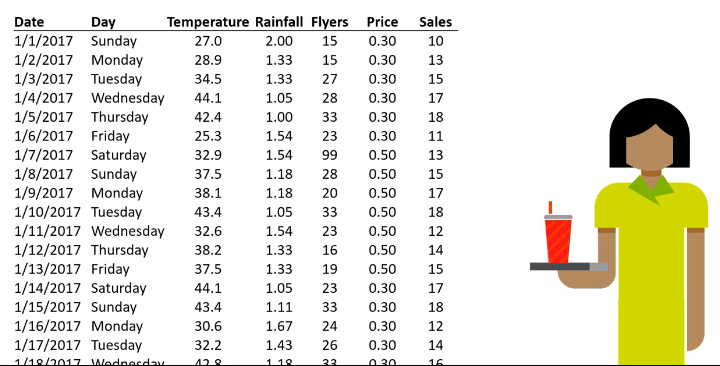
همونطور که مشخصه، رُزی تاریخ (date)، روز هفته (day)، دما (temperature)، میزان بارندگی (rainfall)، تعداد برگههای تبلیغاتی که پخش کرده (flyers)، قیمت (price) و تعداد فروش (sales) رو ثبت کرده. در نتیجه میتونه آمار فروشش رو تجزیه و تحلیل کنه.
ستون Date از نوع دادهی «زمانی» هستش. این نوع دادهها ترتیب مشخصی دارن. مثلا ۲ ژانویه بعد از ۱ ژانویه و قبل از ۳ ژانویه است و به همین ترتیب. روی این نوع داده میشه عملیات محاسباتی انجام داد که البته متفاوت با عملیات محاسباتیای هستش که روی دادههای عددی انجام میشه.
ستون Day نمونهای از نوع دادهی «متنی» هستش. از این نوع داده میشه برای دسته بندی ردیفها استفاده کرد. مثلا ردیفهای مربوط به روزهای پنجشنبه و جمعه رو به عنوان اطلاعات مربوط به آخر هفته در نظر میگیریم.
بقیه ستونها از نوع دادهی «عددی» هستن. ستونهای دما و بارندگی از نوع اعداد «پیوسته» و ستونهای آگهی و فروش از نوع اعداد «گسسته» هستن. وقتی میگیم عدد فروش از نوع گسسته است، یعنی تعداد فروش نمیتونه مثلا ده تا و نیم باشه، یا ده تاست یا یازده تا.
اما ستون قیمت داستانش یه مقدار متفاوته. با وجود اینکه از نظر مفهومی نوع دادهی عددیش از نوع پیوسته است، اما اگه به مقادیر نگاه کنیم میبینیم که تعداد مشخصی قیمت در ردیفها ذکر شده: 0.30 و 0.50. بنابراین قیمت رو هم از نوع دادهی گسسته در نظر میگیریم.
یکی از معمولترین عملیات روی دادهها، «مرتبسازی» هستش. بر اساس اینکه دادهها بر چه مبنایی مرتب میشن، میشه اطلاعات متفاوتی استخراج کرد.
مثلا وقتی دادههای بالا رو بر اساس میزان فروش مرتب کنیم (ستون Sales)، تعیین اینکه کمترین و بیشترین فروش در چه دمایی بوده خیلی سریع و راحت انجام میشه. دادهها میتونن به صورت «صعودی» (سمت چپ) یا «نزولی» (سمت راست) مرتب بشن:
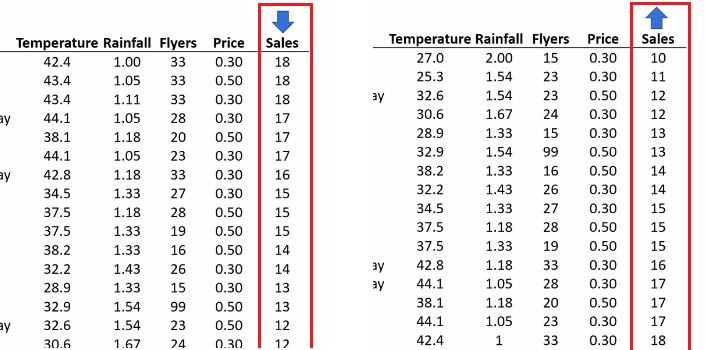
حالا اگه دادهها رو بر اساس ستون آگهیها (Flyers) به صورت نزولی مرتب کنیم، به یه مورد تقریبا غیرعادی در دادهها میرسیم. بیشترین تعداد برگهی آگهی که تو یه روز پخش شده 99 تاست که با تعداد بعد از خودش، یعنی 33 تفاوت فاحشی داره:
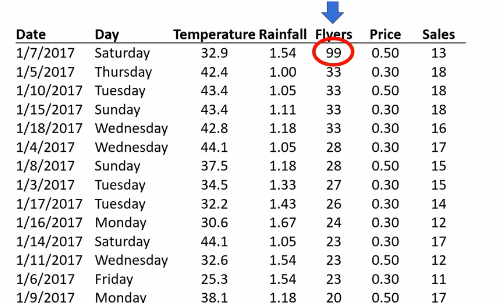
ممکنه رُزی یه روز اتفاقا تعداد زیادی برگهی آگهی پخش کرده باشه. یا یه اشتباه تایپی باشه، مثلا به جای 19 نوشته 99. ما نمیدونیم کدومشون بوده، اما خوبه که موقع تجزیه و تحلیل بدونیم که همچین دادهی غیرعادیای اینجا داریم.
غیر از مرتبسازی، «فیلتر» فیلدها هم اطلاعات مفیدی به ما میده. مثلا برای بررسی فروش در روزهایی که دمای هوا کمتر از ۳۰ درجه بوده، میتونیم ستون Temperature رو با اعداد کوچکتر از ۳۰ فیلتر کنیم.
گاهی برحسب نیاز میشه «فیلدهای جدید»ی بر اساس فیلدهای موجود اضافه کرد. مثلا فیلد درآمد (Revenue) رو میشه با ضرب فیلدهای قیمت (Price) و تعداد فروش (Sales) اضافه کرد. همچنین با جمع مقادیر یه فیلد، مثلا درآمد، میشه به «دادهی جدید»ی مثل درآمد کل رسید:

نکتهی قابل ذکر دیگه اینه که وقتی حجم دادهها کمه، شاید بشه با یه نگاه چشمی دادهها رو با هم مقایسه کرد. اما وقتی تعداد ردیفها زیاد شد، مقایسهی دادهها کار سختی میشه. اینطور مواقع میشه از روشهایی برای سادهسازی کار استفاده کرد.
یه روش استفاده از رنگ هستش. مثلا تو ستون دما، دماهای بالاتر رو میشه پر رنگتر نشون داد. یا مثلا بر اساس شرط خاصی، از رنگهای مختلفی استفاده کرد. به فرض تو ستون درآمد، ۲۵ درصد از بالاترین درآمدها با رنگ سبز و ۲۵ درصد از پایینترین درآمدها با رنگ قرمز نشون داده بشه. حتی از نمودار میلهای هم برای مقایسهی دادهها میشه استفاده کرد. به فرض در ستون میزان بارش، بارش بیشتر دارای میلهی بلندتری خواهد بود:
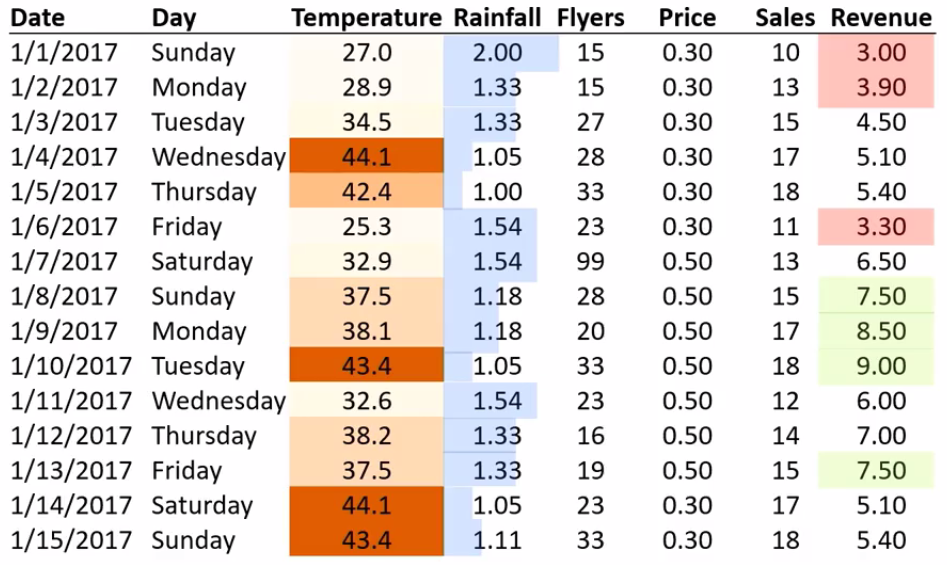
به عنوان یه مثال، تو تصویر بالا میشه خیلی سریع و راحت متوجه شد که پایینترین درآمد تو روزایی بوده که بیشترین بارندگی رو داشتن.
بخش سوم - نصویرسازی از دادهها و تحلیل آنها
